 |
|
|
"Crack Me If You Can" - DEFCON 2010 |
|
Back to [Teams] [Top]
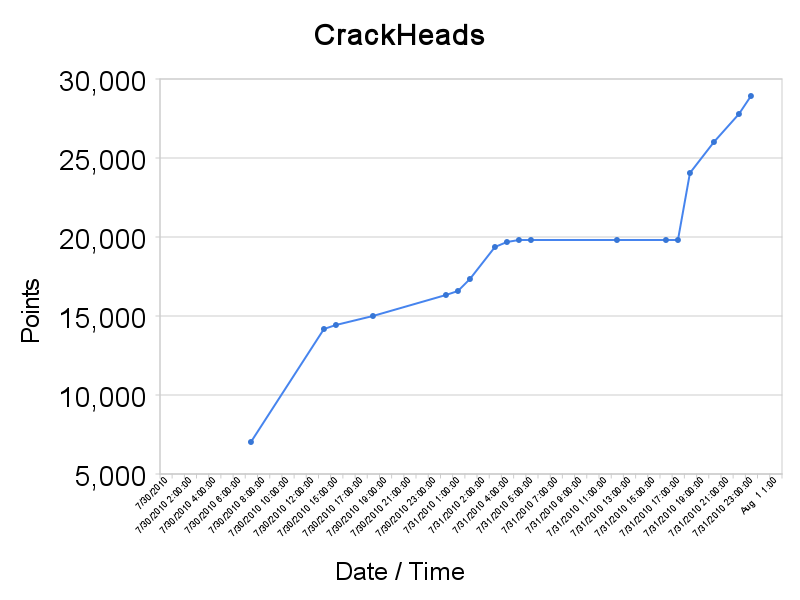
Team CrackHeads Link to original writeup (external) Graph of CrackHeads' score over time Resources
Also, thanks to Solar Designer and all the John contributers. John is
great software and using it makes cracking fun. Without John I doubt a
contest like this would even have been possible.
PRE-CONTEST
I have put a lot of engineering time into cracking various hashes both
for my job here at UC San Diego as well as for fun cracking things like
PHPBB and Carders.CC.
Ron Bowes found out about the contest and suggested we put together a
team. I realized that my process of cracking is somewhat chaotic so I
spent many hours of free time in July organizing, cleaning up word
lists, researching Amazon EC2, etc.
I decided that I would do most of my cracking out of Amazon EC2 and my
friend and co-worker Tom Maddock would crack with his ATI Video card
using oclHashcat and he would manage our 2000 core-hours of cluster
time.
I built out a pretty nice Gentoo-based Amazon Machine Image (AMI) and I
grabbed john code, patches, etc and rolled them into the image. I
also rolled in some perl scripts, Matt Weir's probabilistic cracker,
and various other supporting code.
I had the foresight to hack up a perl script and stuff it in cron to
automatically monitor the john.pot file and email a team mailing list
the new cracks every 5 minutes. By building this into the AMI
before-hand much of the maintenance work of managing cracks was
automated. This saved so much time. During the contest I wrote a
procmail script to automatically collect the new cracks from the emails
and prep them for manual submission.
Since I didn't know what sort of passwords the contest would use I also
spent quite a bit of time building and cleaning wordlists and
organizing them. This turned out to be nearly useless.
RESOURCES
On my end:
I had two Dell servers each with 8 cores running at 2.8 GHz. I ended
up not using these for any CPU time. Instead I just used them to
manage wordlists, write code, submit cracks, etc.
I also had my Gentoo AMI built out for cracking and the ability to
spawn up to 20 instances on EC2. I peaked at 17 during the contest.
Over the 48 hours I averaged roughly 12 instances running, each was
averaging about 80% load. That's roughly 12 * 8 * .8 = 77 core-hours
of processing. This cost me $185.
On Tom's end:
Tom owns an ATI 5850 video card that he used oclHashcat on. We weren't
sure how best to use the card and we ended up letting it sit idle for
about half the time. It is hard to gauge how useful the video card
was. Although it only cracked a couple hundred hashes that we didn't
get with John, we used all of our cracked passwords to spot patterns
and to apply more rules to.
Tom also was in charge of our cluster time. See:
http://tritonresource.sdsc.edu/cluster.php
We only had 2000 core-hours, of which we used 1700. That roughly
averages to 35.5 cores running through the 48 hours of the contest.
The cluster is running Rocks 5.3. We only focused on salted hashes
with the cluster. This ended up being mostly wasted resources.
Magnum's MPI patch had several problems that prevented it from
working. Tom spent about 12 hours working on getting it going. Most
of the problems had to do with file locking and storing passwords in
the john.pot file. There was also an issue with all cores starting at
the same place and cracking the same things rather than distributing
the work for the job. I don't have any more details and I don't know
how Tom resolved these.
STRATEGY
Initially my strategy was going to be to run my highest quality English
wordlist with john --rules and then based on that, adapt. I was also
planning on running Matt's Probabilistic Cracker trained on a cleaned
up set of RockYou + PHPBB.
I fired up 7 EC2 spot instances of the high-CPU (c1.xlarge) machines.
I dedicated each machine to a hash type: bcrypt, crypt, Oracle, SSHA,
FreeBSD-MD5, SHA, Windows (NTLM + LM). Spot instances machines are
priced on a fluctuating marked based on demand and I was paying roughly
30 cents per machine per hour.
See:
I was using the "High-CPU Extra Large Instance".
The English wordlist sucked against the passwords in the contest and
Matt's cracker (with the training I did) was even worse. It became
clear that I wasn't going to crack any bcrypt hashes and I wasn't sure
I was doing anything useful on the Oracle hashes.
In the first 12 hours I made almost no progress with any of the
non-Windows hashes. I just got each instance cracking what I thought
was the most efficient use of the CPUs and left them there doing their
thing.
I focused much of my early engineering time on cracking the NTLM
hashes. Once I had exhausted my quality worldlists and rules, I
started feeding already cracked passwords back through john rules which
did a decent job of cracking more.
I got 4 hours of sleep Friday morning. When I got up I had to do 5
hours of classwork for a paper due.
ADAPTATIONS
It was obvious by Friday afternoon that the our strategy was not
working well. I wanted to apply patterns to our already cracked but
I'm not very good with John rules.
I started out by creating a list of common source words:
I trained Matt's guesses on the already cracked passwords and fed the
common lists into it. This made great progress on the NTLM hashes but
because of the slowness of the salted/iterated hashes it only got a
few dozen. I retrained on updated cracking progress many times and
continued to get good results.
Because Matt's program eats up a ton of memory the more guesses it
makes (like with NTML) I decided to start 2 high-CPU, high memory boxes
on EC2. These cost $2.68 per instance, per hour. I paid for 5
instance-hours total. These instances are not worth the money unless
you have a need to use the memory. I ended up not being able to use
the memory. I did benefit from the slightly faster CPUs though.
We decided that the cluster would allow us to make big progress on the
slow hashes so I created a 4 GB file with Matt's probabilistic cracker
and we ran that on through crypt, ssha, and FreeBSD-MD5. This is how
we made most of our progress on the non-Windows hashes.
I decided it would be faster for me to write some C code to mangle
words based on desired patterns rather than learn and test John rules.
I'm not sure this is actually true or not but I went with C anyways.
This word mangling program was by far our biggest breakthrough of the
whole contest. I think the biggest issue with stand-alone mangling
programs that when you stuff in a chain of pipes is that they rob John
of CPU time. To reduce that impact, I hacked something together that
doesn't use malloc(), doesn't use printf() and buffers the output to
reduces calls to write() by printing a large number of guesses all at
once.
The program takes input and can do things like prepend, insert, or
append numbers, symbols, or any character. It can also leet-speak,
tOgGle cAsE, transpose eltters, replace charakterz, etc.
I know John rules can do all these things and more so this isn't
exactly a huge breakthrough. I'm not sure how easy it is to "stack"
John rules while minimizing (but not eliminating) duplicates but my
program handles that naturally by the nature of recursion.
It was hacked together during the contest and surely has lots of bugs
but you can grab the code here:
http://noh.ucsd.edu/~bmenrigh/mengele.tar.gz
I used my common_short.txt file to great success with my mengele
program.
MISTAKES
Because all the hash formats were worth the same amount, we basically
wasted all of our cluster time cracking a few thousand non-Windows
hashes. I also only used about 1/3rd of my Amazon EC2 time focused on
Windows hashes. Cracking NTLM hashes seemed to be the key to winning
the contest. The majority of our points came from cracking NTLM and I
know we could have cracked a whole bunch more if I hadn't wasted so
much engineering time cracking the salted passwords. We could have
done a lot with the cluster against NTLM too.
We didn't know how to make use of oclHashcat. In retrospect we should
have written a script to generate patterns and then feed them into
Hashcat. Letting it sit idle for so many hours was a huge mistake.
I was planning on dedicating 1 EC2 instance to each set of admin
hashes. I made the mistake of glancing through the released hashes and
concluding that there was no differentiator between admin and user
hashes. It wasn't until a few hours before the end of the contest that
I realised it was easy to tell them apart. I would have started up 14
spot instances instead of 7 and cracked just admin hashes on one
instance. This would have helped negate the salting and overall
slowness by focusing work on just high value hashes.
I should have realized that bcrypt was a lost cause and used the
machine for other tasks.
I had a machine trying to crack the Oracle hashes. Towards the end I
had heard from enough people that they were, indeed, Oracle hashes that
I decided to throw more resources at them. I guessed that each of the
1000 were admin hashes. I started up 4 more high-CPU instances and
split the 1000 hashes into 4 chunks of 256. I split the input list to
me mangled into chunks of 8. I started 8 jobs against each group of
hashes for a total of 32 cores going all out. I left these going for 6
hours and I still did not crack a single one. Even using the most
efficient mangling configuration for mengele, I still didn't crack a
single one. These resources would have been much better focused on
NTLM on SSHA.
SUGGESTIONS
Here is my idea for a point system:
Have 3 different types of plain text -- easy, medium, and hard. Easy
could be worth 1 point, medium 2, and hard 5.
Have a multiplier for the hash type. Make LM .5, NTLM 1, SHA 2, SSHA
and CRYPT 10, FreeBSD MD5 25, Bcrypt 100.
Make an admin hash a multiplier of 10.
That is, if you crack a medium NTLM hash it is worth 2 * 1 = 2 points.
If you crack a hard NTLM, admin hash it is worth 5 * 1 * 10 = 50
points. If you crack a medium admin bcrypt hash it is worth 2 * 100 *
10 = 2000 points.
Also, give teams that are leading in a hash type or plaintext type a
point boost. That is, the team that has the most SSHA cracks gets an
extra 1000 points. The team that has the most admin hashes cracked
gets 1000 points. The team that has the most easy hashes cracked gets
1000 points. These bonus points would move from team to team depending
on who is leading in each category.
Our organization has complexity requirements. Usually the people that
were going to pick the password "password" don't satisfy the complexity
requirement by choosing "#P4ssW!or2010D", they choose "Password1!".
Only a few people in the organization will go all out. This contest
seemed to be about going after the people who are TRYING to make secure
passwords.
Brandon
|
{kind=link}
Please contact us if you would like more information about our services, tools, or careers with us.
HOME : SOLUTIONS : RESULTS : TOOLS : RESOURCES : ABOUT KORELOGIC
Privacy Policy : Copyright 2026 KoreLogic Security. All rights reserved