| Active Members
| 4
|
| Handles
| bartavelle, unspecified
|
| Software
| John the Ripper, custom distributed cracking code
|
| Hardware
| During most of the contest: 123 assorted CPU cores.
At peak: 204 assorted CPU cores.
|
[MEMBERS]
The "active" members were me and a couple friends. Another one handled
the LM hashes part. Quite a few people helped us by running our software
on computers they owned. Thanks to them!
[PRE-CONTEST]
Me and one of the team members have been working for a few weeks on a
automated password cracking system. This system would also provide
statistics, graphics that could be copied and pasted into reports,
automatic analysis and stuff like that. It could also be used to perform
other computing tasks.
While the "interface" part of the system is quite mature by now, the
actual cracking part was not truly tested. Early tests, a week before
the contest, highlighted design errors that absolutely needed to be
addressed for it to scale for this contest. We spent the days before the
contest rewriting part of the system, and doing not much else.
Some early advertising was also done so that people would join our
"cluster" system, but only one answered.
[CONTEST TIME]
When the contest started, we only had a limited set of resources
available for various reasons. The first hours were spent recruiting.
After that, I was moving out 700km away and was just packing my stuff,
leaving only two members on the team to accomplish things.
The computing resources were targeted at all hashes, with about 3 hours
spend for each. After that was done, it was decided that we would go for
the MD5 crypt hashes, as my implementation should be faster than the
other competitors.
I spent most of my spare time fixing the software and creating the
infrastructure (such as the automatic submission of the passwords)
required for the contest.
We then experienced a huge client crash (not yet resolved). I had the
brilliant idea to reset the environment by trashing the database,
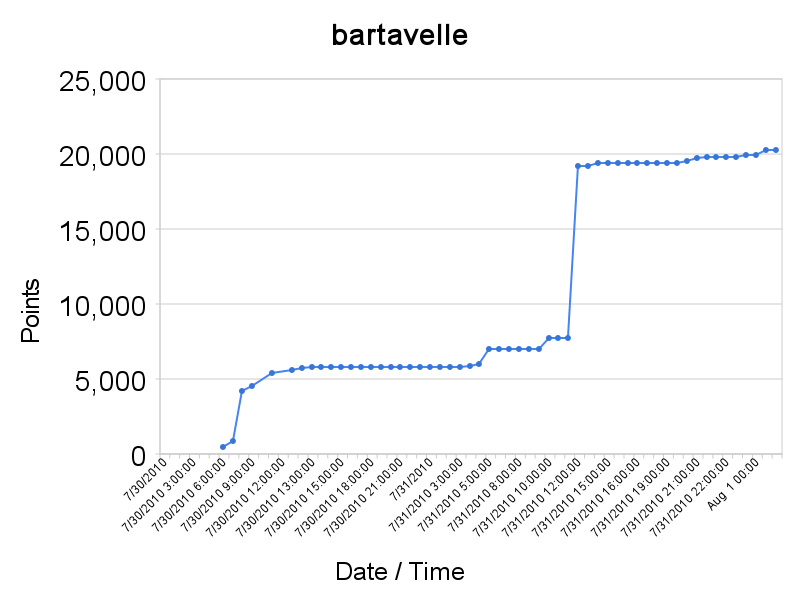
without dumping it first. I lost most of my stats during that process.
The last 20 hours were spent by the cluster crunching the md5 admin
hashes, with no success. At the same time, the LM job finished, and the
two team members left were busy trying to figure out the patterns.
[RESOURCES]
John the Ripper was used exclusively, except for the LM hashes cracking.
For the CPU throughput during the last 20 hours (multiply by 18 for the
actual hashing operations):
http://bigbox.banquise.net/jtr/cpus.txt
http://bigbox.banquise.net/jtr/tested.png
(The last graph shows cracking done after the end of the contest).
We had more resources available before the crash :
+------+-------------------------------------------------+
| core | name |
+------+-------------------------------------------------+
| 8 | AMD Athlon(tm) 64 X2 Dual Core Processor 5600+ |
| 4 | AMD Athlon(tm) II X2 B22 Processor |
| 2 | Genuine Intel(R) CPU T2500 @ 2.00GHz |
| 4 | Intel(R) Atom(TM) CPU 330 @ 1.60GHz |
| 2 | Intel(R) Celeron(R) CPU 220 @ 1.20GHz |
| 2 | Intel(R) Celeron(R) CPU E1400 @ 2.00GHz |
| 1 | Intel(R) Celeron(R) CPU 2.60GHz |
| 1 | Intel(R) Celeron(R) CPU 2.66GHz |
| 4 | Intel(R) Core(TM) i5 CPU M 540 @ 2.53GHz |
| 8 | Intel(R) Core(TM) i7 CPU 860 @ 2.80GHz |
| 8 | Intel(R) Core(TM) i7 CPU 950 @ 3.07GHz |
| 2 | Intel(R) Core(TM)2 CPU T7400 @ 2.16GHz |
| 2 | Intel(R) Core(TM)2 Duo CPU E6750 @ 2.66GHz |
| 2 | Intel(R) Core(TM)2 Duo CPU E8400 @ 3.00GHz |
| 2 | Intel(R) Core(TM)2 Duo CPU E8500 @ 3.16GHz |
| 4 | Intel(R) Core(TM)2 Quad CPU Q9550 @ 2.83GHz |
| 4 | Intel(R) Core(TM)2 Quad CPU Q6600 @ 2.40GHz |
| 4 | Intel(R) Core(TM)2 Quad CPU Q8300 @ 2.50GHz |
| 4 | Intel(R) Core(TM)2 Quad CPU Q9400 @ 2.66GHz |
| 4 | Intel(R) Pentium(R) 4 CPU 2.80GHz |
| 2 | Intel(R) Xeon(R) CPU 5160 @ 3.00GHz |
| 16 | Intel(R) Xeon(R) CPU E5405 @ 2.00GHz |
| 4 | Intel(R) Xeon(R) CPU E5420 @ 2.50GHz |
| 8 | Intel(R) Xeon(R) CPU E5504 @ 2.00GHz |
| 24 | Intel(R) Xeon(R) CPU E5506 @ 2.13GHz |
| 2 | Intel(R) Xeon(R) CPU E5540 @ 2.53GHz |
| 32 | Intel(R) Xeon(R) CPU E7440 @ 2.40GHz |
| 8 | Intel(R) Xeon(R) CPU X5472 @ 3.00GHz |
| 24 | Intel(R) Xeon(TM) CPU 3.60GHz |
| 2 | Pentium(R) Dual-Core CPU E6500 @ 2.93GHz |
| 8 | Quad-Core Intel Xeon |
| 1 | VIA Esther processor 2000MHz |
| 1 | VIA Nano processor U2250 (1.6GHz Capable) |
+------+-------------------------------------------------+
[WHAT WENT WRONG]
First of all, the preparation was not sufficient. The software should
have been finished beforehand (wordlist support was not in yet),
debugged (there was this huge crash in the middle of the contest where
we lost many clients, with minor issues).
One of the biggest problem was the work distribution. For the sake of
simplicity, a design decision was that cracking would be distributed
using the markov system in jtR. The work space would then be cut in
equal slices and these slices would be distributed to the clients.
The problem was that some clients were *really* slower than the fastest,
which was used as a basis for the slice size determination. It turned
out that what would last 10 minutes on the fastest core could last 2
hours on another. Some slices were never completed in time by the really
slow ones.
Too much time was spent cracking the MD5-crypt whereas with a lot of
computers it could have been possible to crack more MD4s or SHAs and gain
a better insight on the patterns used. The MD5 job that was last run
only completed 20% of its assigned search space by the end of the
contest. The parameters were really badly selected.
This large computing force accounted for only 30% of the score of this team.
Finally, this platform was designed to crack "normal" (weak) passwords
and to require minimal interaction. It was not suited at all for this
contest.
[WHAT WENT RIGHT]
The remaining 70% of the score was gained by two members of the team,
using JtR and some ad-hoc script that generated candidate passwords. The
server didn't scale too horribly, even across slow connexions, and I
managed to only break a couple glasses during my 700km move.
[EPILOGUE]
I'll probably write some stats about what could have been done if the
work had been targeted any other way with the cluster. But here is an
interesting fact. The weaker password of the MD5 admin list had strength
234 with my training file (it was "John3"). If I knew that there was a
password with strength 234, it would have required about 17 hours of
computation, using all the previously mentioned resources to be sure it
was cracked. Getting a second would have taken 143 hours.
I retrained the stats file during the contest using already cracked
passwords. If I had reset everything to use the new stat file (a feature
not available right now), it would have taken less than an hour to crack
two passwords ("John3" and "M20107y"). The next one would have consumed
77 hours.
[WHAT SHOULD HAVE BEEN DONE]
It was not obvious when the challenge started, but the preferred
resolution method for people with large clusters looks like :
- crack hashes using whatever "not too smart" method (JtR incremental
mode, markov mode, etc.)
- find patterns that could be translated to mangling rules and the
corresponding wordlist
- use a system to queue wordlists / mangling rules job units and to
schedule them on your cores
- rinse an repeat

{kind=link}
{kind=link}